

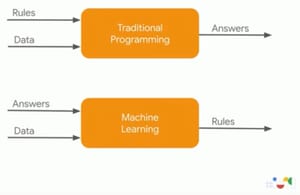
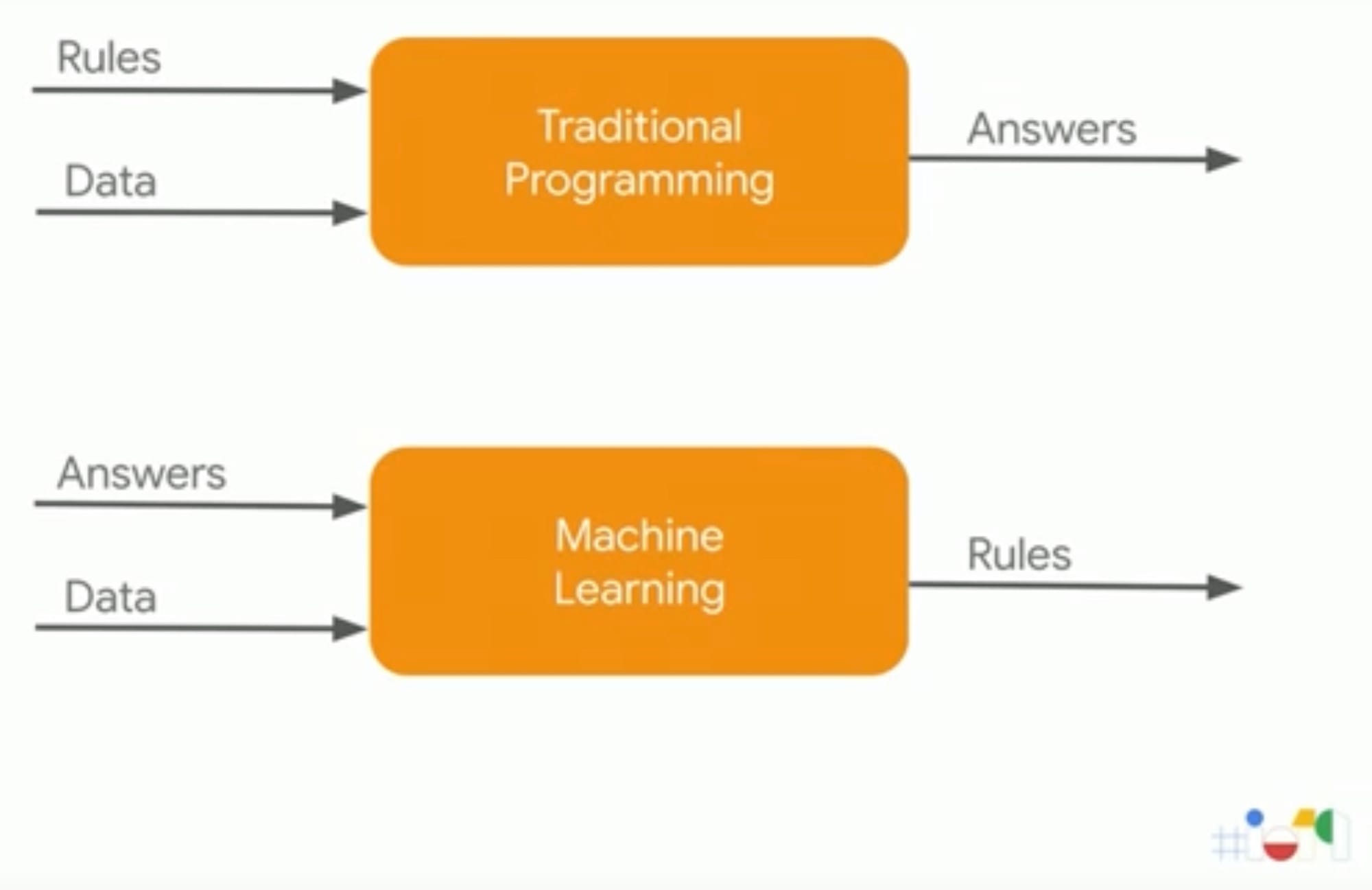
Das Bild stammt von einer Präsentation auf der Google I/O 19 von zwei Vertretern des TensorFlow-Teams bei Google und es stellt eine perfekte Beschreibung von Machine Learning dar. (via)
Software, wie wir sie bisher kannten, war grob so aufgebaut: Wir geben die Regeln (Algorithmen) ein, und die Software wendet diese Regeln auf die Daten ein, die wir einspeisen. Herauskommen die Antworten der Software.
Machine Learning dagegen ist 'ungenauer'. Wir füttern den Machine-Learning-Algorithmus mit 'Antworten' in Form von großen Datenmengen, aus denen der Machine-Learning-Algorithmus sich eine Menge(!) an Regeln erarbeitet, die dann wiederum auf andere Datenmengen angewendet werden können. Auf diesem Weg können komplexe Regelwerke geschaffen werden, die nicht per Hand programmiert werden können.
Ein Beispiel: Wir füttern unsere lernende Maschine mit vielen Bildern von Katzen. Die Software lernt aus der Fülle der Bilder, wie Katzen aussehen können. Das wäre top-down, also mit hart einprogrammierten Regeln, schwierig zu realisieren. Zumindest wenn man möglichst akurat möglichst alle Katzen abdecken möchte.
Gleichzeitig kann hier auch einiges schief gehen, wenn man nicht auf das Learning Set achtet; also die "Antworten" mit denen man den Machine-Learning-Algorithmus füttert. Wer dem Algorithmus beibringen will, wie Adler aussehen, sollte dabei nicht zu viele Bilder mit Adlern auf den Armen ihrer Halter zeigen, oder eine Regel 'lautet' zwangsläufig dann quasi Vogel+Arm=Adler. Das ist, was man data bias nennt. (Hier etwa findet man sieben Formen von üblichen Fehlern bei der Datenauswahl.)
An diesem recht simplen Beispiel sieht man auch,
- dass es nicht zwingend so ist, dass "mehr Daten" zu akkuraterem Machine Learning führt. Es geht eher um "bessere Daten". Also bessere Antworten zum Füttern.
- dass es einen Unterschied macht, wie präzise die Daten sind und etwa branchenübergreifende Übersetzungen von Machine-Learning-Erfolgen auf absehbare Zeit unrealisitisch sind.
Was heute mit Machine Learning erfolgreich gebaut wird, ist teilweise phänomenal, hat aber nichts mit allgemeiner künstlicher Intelligenz a la Skynet zu tun. Deshalb wird jeder gesellschaftliche Bereich, jede Branche, einen eigenen Weg gehen, ohne dass "Machine Learning als Sektor" von einem Unternehmen dominiert wird. Man vergleiche den Einsatz von Machine Learning eher mit dem Einsatz von Datenbanken und Computern allgemein.
Machine Learning ermöglicht uns, Computer auf neue Aufgabenfelder anzusetzen. Neben Katzenbildern etwa Früherkennung von Krebs.
a16z-Analyst Benedict Evans schreibt auf Twitter:
We're used to software that give yes/no answers - is there a match or not? Is this licence plate flagged? is that credit card valid? But ML doesn't say yes/no. It says 'maybe/maybe not/probably' answers. And, if you tell a cop or judge a 'maybe' is a MATCH, bad things will follow
Aber damit einher geht auch ein gesellschaftlich notwendiges Umlernen wie wir Software und computergenerierte Ergebnisse bewerten. Es macht einen großen Unterschied, wenn Software nicht mehr nur Ja/Nein-Fragen mit ja und nein beantworten kann, sondern komplexere Sachverhalte mit 'vielleicht/vielleicht nicht/wahrscheinlich' beantwortet.
Mehr noch, das muss sich zwingend in den User Interfaces widerspiegeln.
Machine Learning ist nicht 'vorhersehbare' (überschaubare, nachvollziehbare) Mathematik wie es 'klassische' Software ist. Machine Learning ist Stochastik, so wie wir Menschen Stochastik im Alltag verwenden. Auch wir können ein Tier sehen und es zunächst einer falschen Tiergattung zuordnen.
Der Unterschied liegt, auch hier, zwischen Bottom-up vs top-down. Mit allen Vorteilen und Nachteilen.
Es ist das Gleiche wie mit Plattformen mit user generated content und klassischen Medienorganisationen. Die Plattformen ermöglichen mehr, sehr viel mehr, als die klassischen Medienorganisationen, weil bottom-up 'Überraschendes' nach oben kommen kann. Gleichzeitig kann auf diesem Weg anderes 'schief' gehen. Nichts ist perfekt.
Das beste Bild für Artificial Intelligence ist nach wie vor, Intelligence wie in Intelligence Service zu verstehen. Tiefe Einblicke, die man nur auf diesem Weg bekommen kann, die aber nicht automatisch fehlerfrei sind. Ganz im Gegenteil. Künstliche Intelligenz ist deshalb gar keine gute Beschreibung für Machine Learning et al. Denn es geht hier weniger um "Intelligenz", was auch immer man darunter verstehen mag, und mehr um Einsichten, Ableitungen, Erkenntnisse.
(Siehe zum Thema auch meine kurzen Ausführungen in neunetz.fm Der Tag 32 vom Juni diesen Jahres)