

Und was, wenn OpenAI es doch nicht schaffen wird?
Der unabhängige Analyst Benedict Evans machte letzte Woche im Stratechery-Interview eine wichtige Beobachtung, die mich nicht mehr loslässt:
Wie wir wissen, hat ChatGPT zwar über 800 Millionen monatlich aktive Nutzer:innen (u.a. TechCrunch Oktober 2025), aber da OpenAI nur wöchentlich aktive, nicht täglich aktive Nutzer:innen angibt, können wir auch ohne offizielle Zahlen davon ausgehen, dass der überwiegende Anteil davon ChatGPT „nur“ einmal die Woche benutzt. (Was WAU zur imposantesten unter den verfügbaren Zahlen macht.)
Evans Beobachtung: Wer ChatGPT nur selten, also einmal die Woche, nutzt und die Gratis‑Version künftig mit Werbung bekommt, liefert zu wenig Nutzungssignale, damit die Werbung wirklich gut und zielgenau werden könnte. Und die Leute, die es so viel nutzen, dass es sich für gute Werbung lohnen würde, sind genau die, die typischerweise ein Abo zahlen und dann gar keine Werbung mehr sehen.
Im Vergleich dazu: Der TikTok-Deutschland-Chef sagte mir letztes Jahr, dass Deutsche im Schnitt 90 Minuten am Tag auf TikTok verbringen.
Man sollte bei alldem nicht vergessen, dass Produkte wie ChatGPT oder Claude noch am Anfang ihrer Evolution stehen, sie sind erst drei Jahre alt, aber das ändert nichts daran, dass hier und jetzt der Erlösstrom Werbung eventuell zu wenig den kostenintensiven Betrieb entlasten wird...vorsichtig ausgedrückt.
Marcel
Im Fokus dieser Ausgabe:
- Die KI-Mauer: Die prophezeite Mauer ist da; nur geht sie nach oben. Gemini Pro 3 Deep Think erzielt 84,6% auf ARC-AGI-2, einem Benchmark, bei dem KI vor nicht einmal einem Jahr bei 0 bis 4% lag.
Für Mitglieder:
- SpaceX schluckt xAI: Musk plant eine Million Rechenzentren im Orbit. Sechs von elf xAI-Mitgründern sind weg. Erfolgschancen: 50/50.
- Agenten: Karpathy erklärt „Vibe Coding" für beendet und ruft „Agentic Engineering" aus. OpenAI startet Frontier. Azeem Azhar argumentiert, Autonomiedauer sei die einzige KPI, die zählt.
- $660 Mrd. Capex und die Engpässe: Big Tech investiert in einem Jahr mehr als Israels BIP. Nvidia stoppt Gaming-Chips. Microsoft hat zu wenig GPUs für Azure. Und Apple investiert kaum.
- Electric Stack: Drei tiefgehende Analysen erklären, warum Elektrifizierung neben KI das strategische Puzzlestück ist.
- Arbeitsmarkt: Die Jobs verschwinden nicht; sie werden schlechter bezahlt.
- und mehr
Zitate des Tages
I don't know why this week became the tipping point, but nearly every software engineer I've talked to is experiencing some degree of mental health crisis.
Tom Dale auf X
for me the odds that AI is a bubble declined significantly in the last 3 weeks and the odds that we're actually quite under-built for the necessary levels of inference/usage went significantly up
basically I think AI is going to become the home screen of a ludicrously high percentage of white collar workers in the next two years and parallel agents will be deployed in the battlefield of knowledge work at downright Soviet levels
Atlantic-Journalist Derek Thompson auf X
🤖 KI: Die Entwicklung, OMG, die Entwicklung
Metr und die Mauer
Statt über einzelne Modelle zu sprechen, schauen wir uns die allgemeine Entwicklung an. Denn die ist mehr als bemerkenswert.
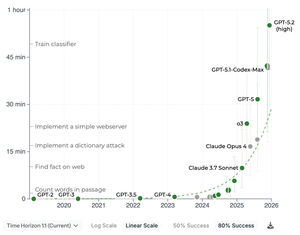
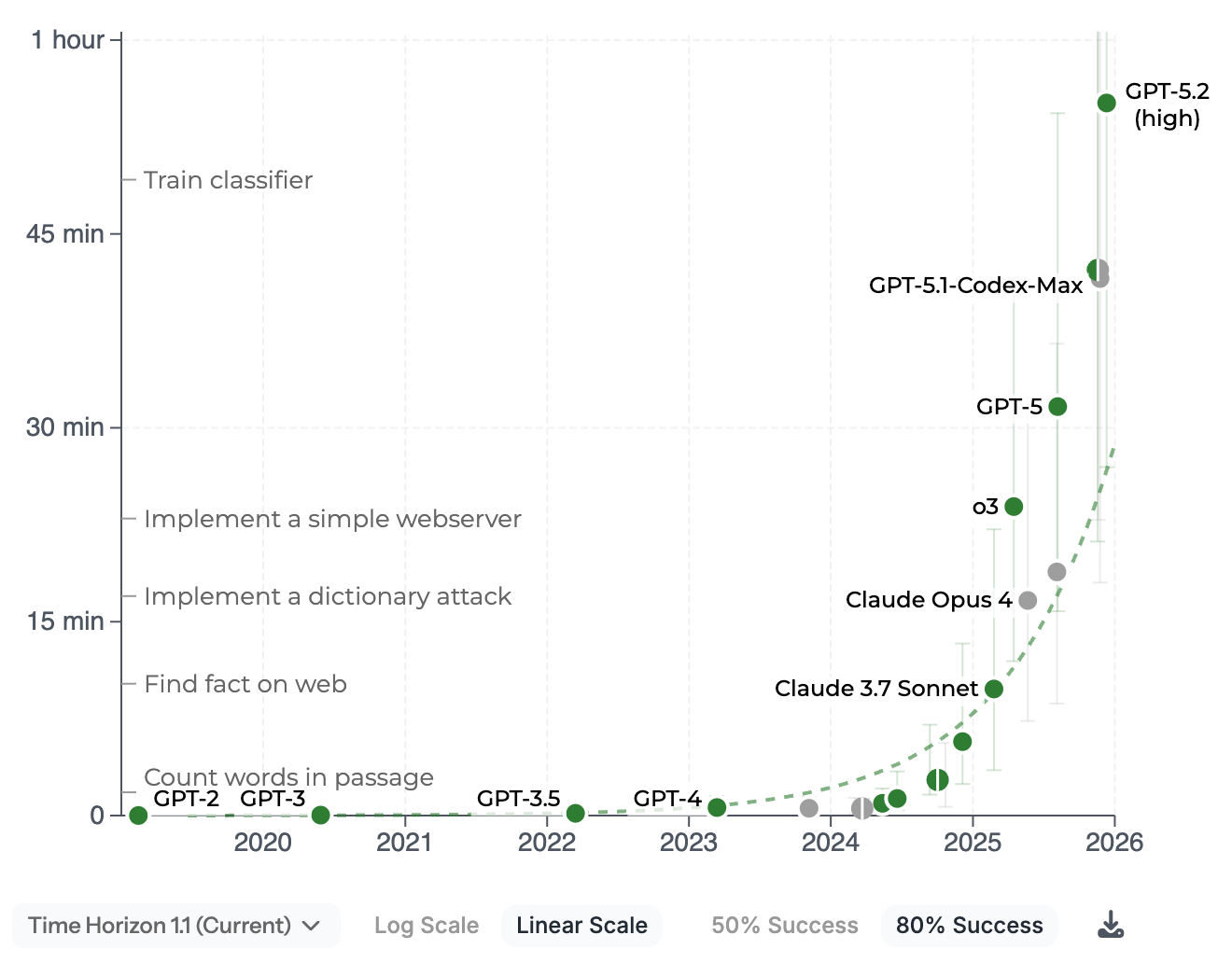
Die jüngsten Modelle von OpenAI und Anthropic, GTP-5.2 (high) und Opus 4.5 im anschaulichen Metr-Graphen. Metr misst, wie hoch die Komplexität der Aufgaben ist, die KI-Modelle in zu 80 bzw. 50 Prozent erfolgreich erledigen können. Komplexität wird daran bemessen, wie lang ein Mensch benötigt, um die gleiche Aufgabe zu erfüllen.
50 Prozent:
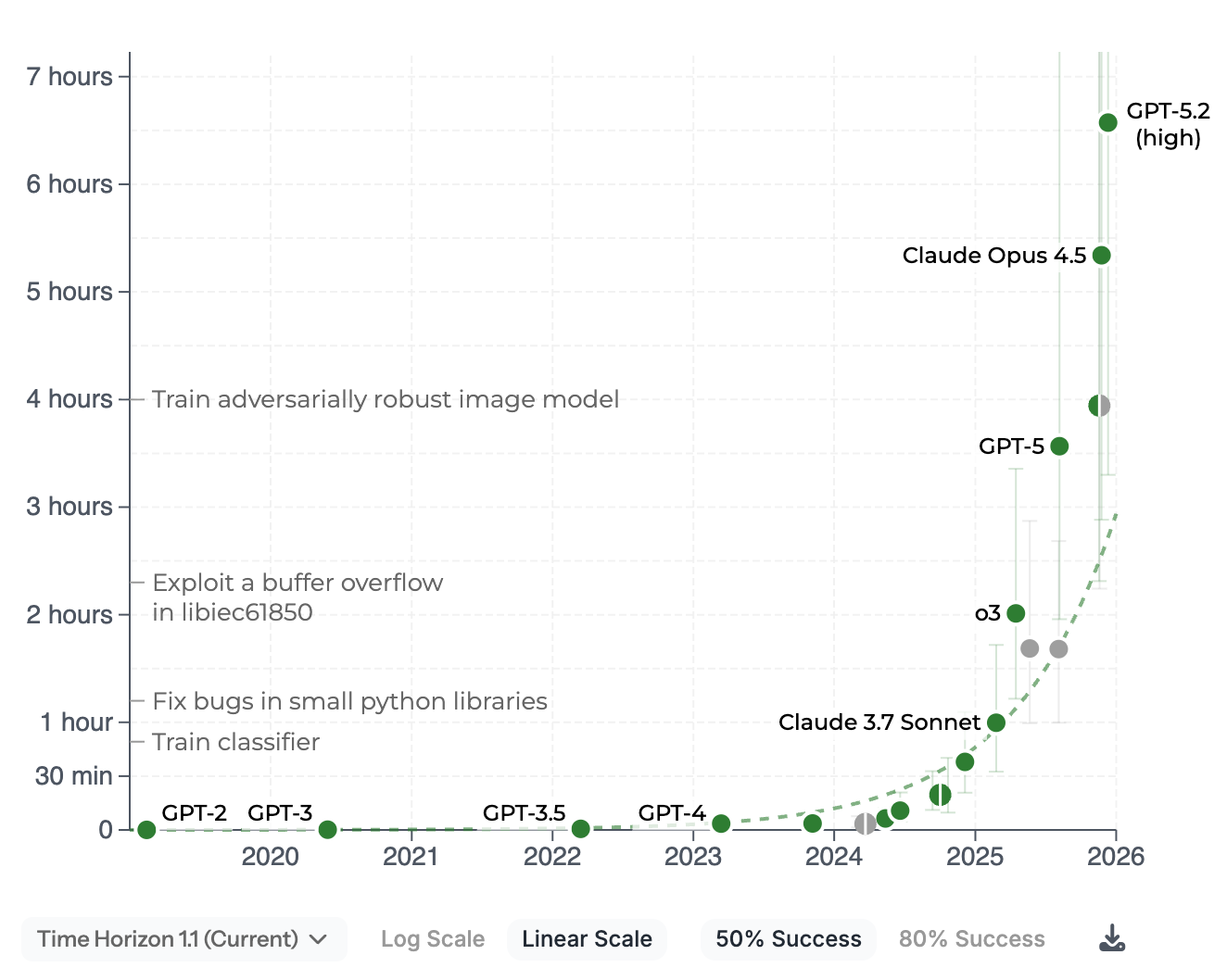
80 Prozent:
Mittlerweile sind GPT-5.3 Codex und Claude Opus 4.6 erschienen. Beide sind optimiert für Programmieraufgaben und werden dementsprechend noch besser abschneiden. (Metr misst nur Programmieraufgaben, weil hier sowohl Zeit als auch Erfolg bei Menschen und bei KI leicht messbar sind.)
Man kann hier bereits sehen, dass die Entwicklung von KI tatsächlich wie von vielen Leuten eine Mauer erreicht hat. Allerdings nicht, wie prophezeit, einen Stillstand, sondern weiter exponentiell ansteigende Fähigkeiten, die so rasant sind, dass wir eine Mauer sehen; eine Mauer, an der die KI-Modelle nach oben schnellen.
Wer sich an „nur 80 Prozent Erfolgrsrate!“ stört, sei auf den Rausschmeißer vom letzten Briefing verwiesen:
Guy with a wish granting machine that only works 10% of the time: man this thing is useless!
Aber damit nicht genug.
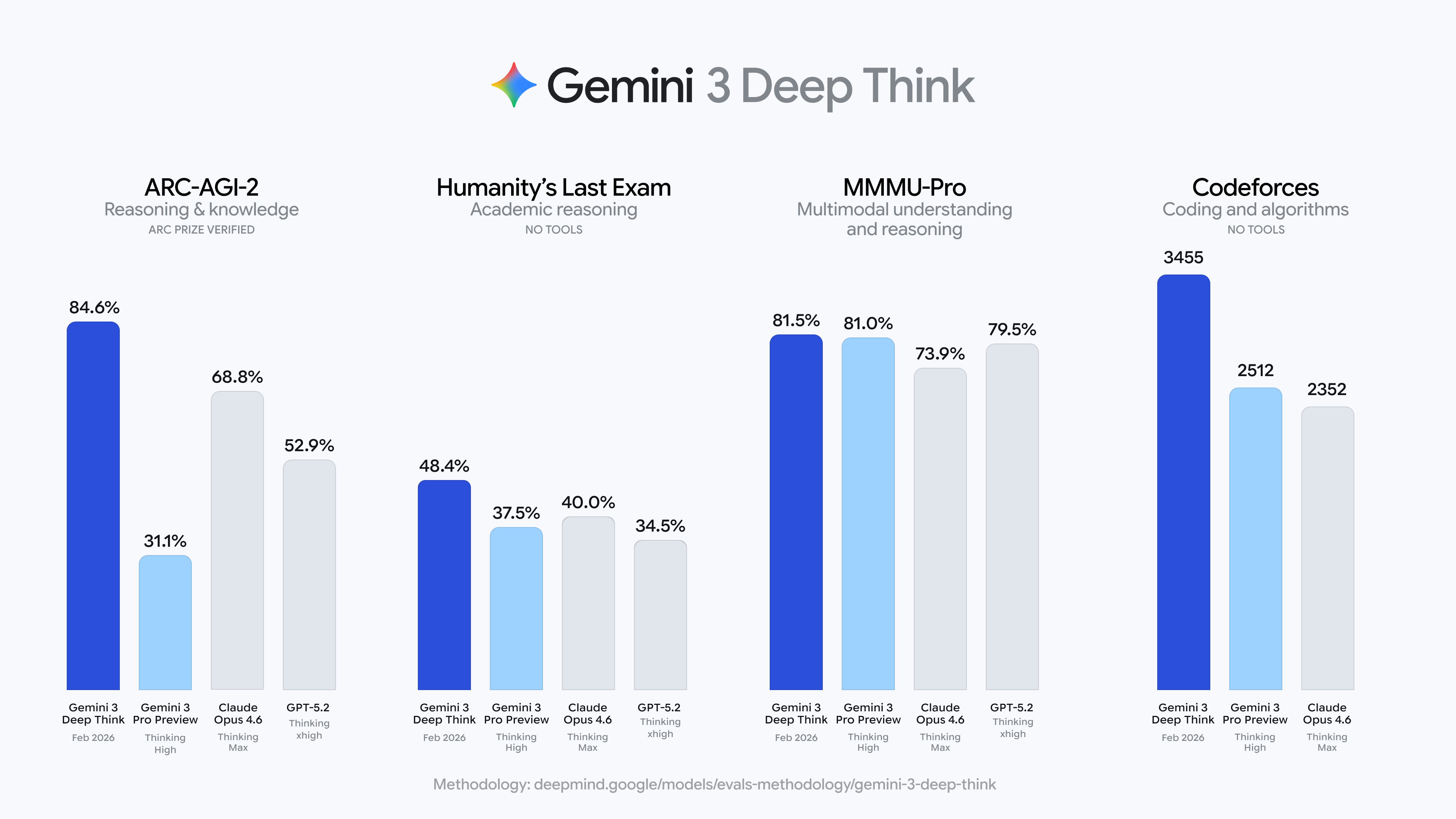
Gemini Pro 3 Deep Think und ARC-AGI 2
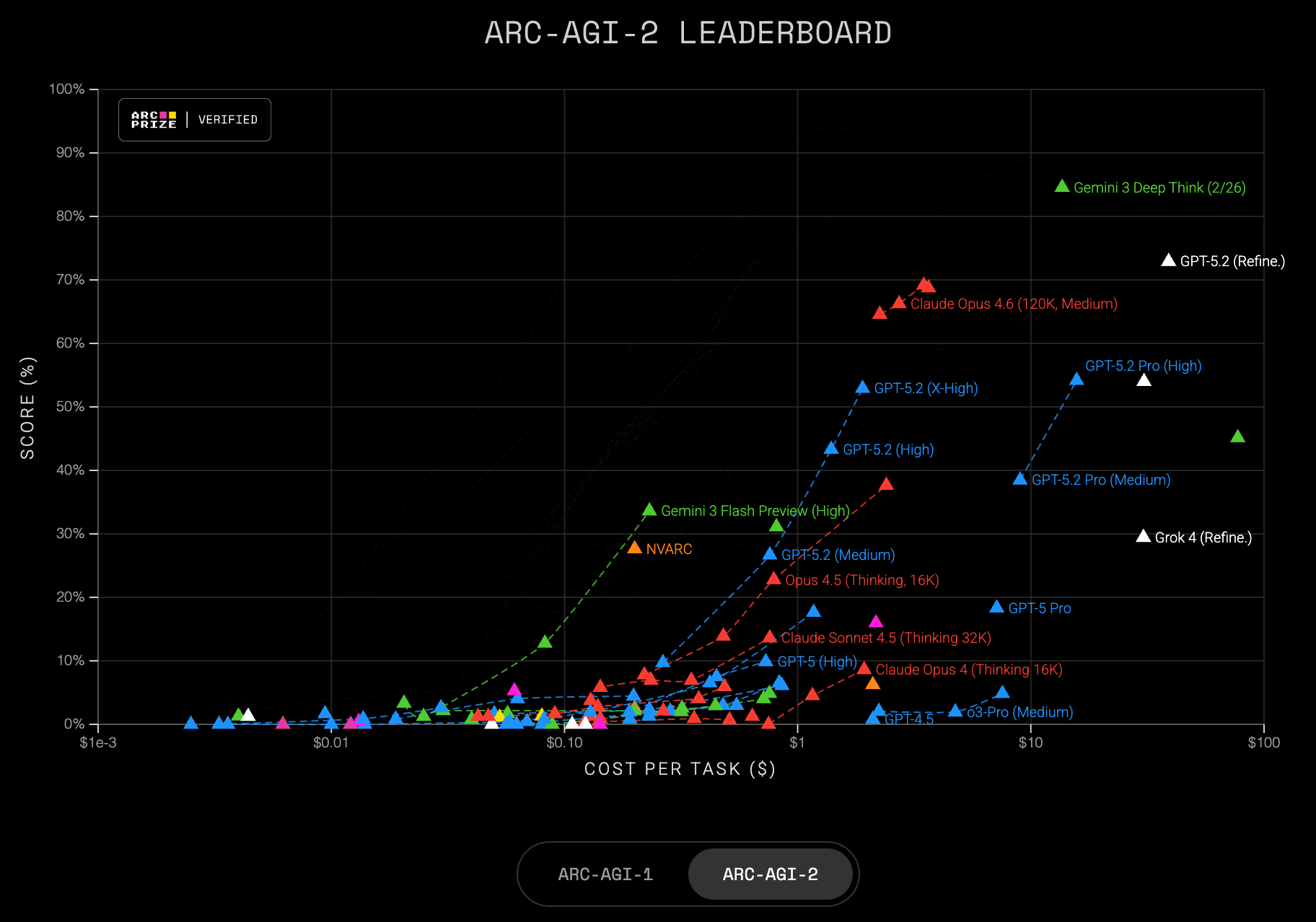
Google Deep Mind hat diese Woche das neue Gemini Pro 3 Deep Think vorgestellt.
Im schweren, nicht öffentlich zugänglichen ARC-AGI-Test schnitt das Modell so ab:
- ARC-AGI-1: 96.0%, $7.17/task
- ARC-AGI-2: 84.6%, $13.62/task
Man sieht in den Charts den Sprung, das Modell ist grün:
Nun muss man zum ARC-AGI Folgendes festhalten:
ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) ist ein Benchmark der ARC Prize Foundation, der den Fortschritt hin zur künstlichen allgemeinen Intelligenz (AGI) messen soll. Er besteht aus rasterbasierten visuellen Denkaufgaben, die für Menschen zumindest in der ersten Inkarnation trivial, für KI aber extrem schwierig sind.
ARC-AGI-1, 2019 von François Chollet eingeführt, umfasste 800 Puzzle-ähnliche Aufgaben mit wenigen Beispielpaaren (ca. drei), die speziell so konzipiert sind, dass sie einfaches "Auswendiglernen" des Trainingsdatensatzes verhindern. Das sollte zu schwer für KI-Modelle sein.
ARC-AGI-2 wurde im März 2025 eingeführt, weil ARC-AGI-1 dann doch zu einfach war. Chollet damals auf X:
Unlike ARC-AGI-1, this new version is not easily brute-forced. Current top AI approaches score 0-4%.
All base LLMs (GPT-4.5, Claude 3.7 Sonnet, Gemini 2, etc.) score 0%. Single-CoT reasoning models (Claude Thinking, R1, o3-mini…) score 0-1%. [...] o3-low would score ~4% (down from 76% on ARC-AGI-1). This is a model that does extensive test-time CoT search.
So this is an extremely unsaturated benchmark – and one that is focused entirely on reasoning, not specialized skills and knowledge.
Nicht einmal ein Jahr nach der Einführung des neuen ARC-AGI-2, wir haben noch Februar, liegt das aktuell beste KI-Modell bei 84,6 Prozent.
But wait, there is more.
Es ist nicht der Sprung in der Qualität, sondern auch in der Effizienz, der beachtenswert ist: Vor drei Monaten benötigte Gemini 138.000 Reasoning-Token, um eine ARC-Aufgabe zu lösen, die Gemini 3 Pro jetzt in 96 bewältigt.
Das ist eine Reduzierung um rund 99,93%.
Money must be funny: Anthropics Umsatz
Anthropic hat eine neue Finanzierungsrunde über 30 Milliarden $ bei einer Bewertung von 380 Milliarden $ abgeschlossen. (Reuters)
Die Umsatz-Run-Rate liegt bei 14 Milliarden Dollar, davon über 2,5 Milliarden allein durch Claude Code (mehr als verdoppelt seit Jahresbeginn); Business-Subscriptions haben sich vervierfacht, Enterprise-Kunden machen inzwischen mehr als die Hälfte der Claude-Code-Umsätze aus.
Die Visualisierung des Umsatzwachstums erzeugt einen der verrücktesten Graphen der Wirtschaftsgeschichte:
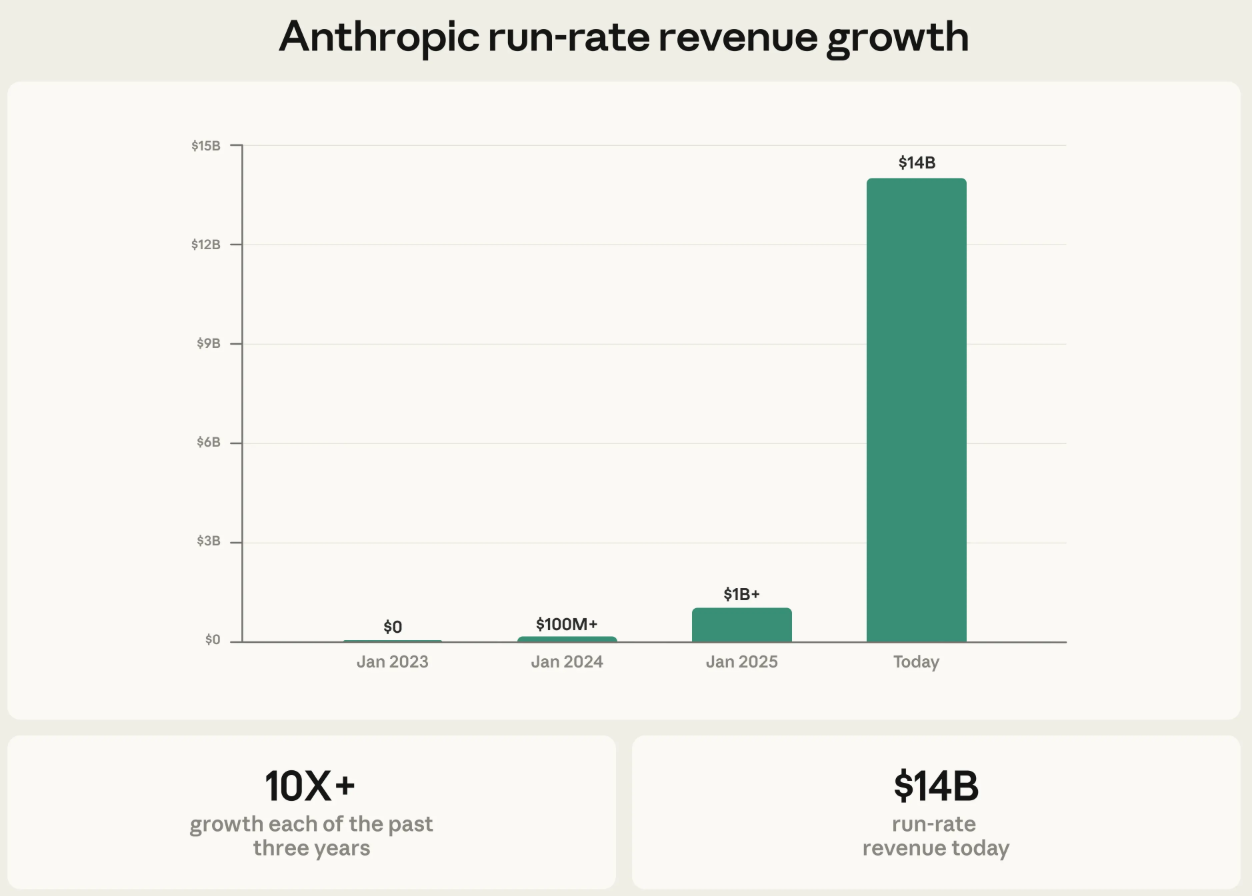
Man könnte fast den Eindruck bekommen, hier ein stark nachgefragtes Produkt zu sehen.
Quelle: Anthropic
The Series G will also power our infrastructure expansion as we make Claude available everywhere our customers are. Claude remains the only frontier AI model available to customers on all three of the world's largest cloud platforms: Amazon Web Services (Bedrock), Google Cloud (Vertex AI), and Microsoft Azure (Foundry). We train and run Claude on a diversified range of AI hardware—AWS Trainium, Google TPUs, and NVIDIA GPUs—which means we can match workloads to the chips best suited for them. This diversity of platforms translates to better performance and greater resilience for the enterprise customers that depend on Claude for critical work.
Verfügbarkeit auf allen drei großen Cloud-Plattformen plus B2B-Fokus sollte den Chart in einem Jahr ähnlich verrückt aussehen lassen.
Es sei denn natürlich, Energie- und Chip-Engpässe machen sich langsam aber sicher spürbar im Umsatzwachstum bemerkbar, was nicht ausgeschlossen ist.
..und in China
Diese Woche allein außerdem in/aus China:
- Letzte Woche: ByteDance veröffentlicht Seedance 2.0 (ging diese Woche viral)
- Kuaishou veröffentlicht Kling 3.0 Video Gen
- Zhipu veröffentlicht GLM-5. 745B Parameter. MIT-Lizenz kommt. 0,11 $ pro Million Token.
- DeepSeek geht von 128K auf 1M Kontext.
- MiniMax veröffentlicht M2.5.
- GLM-5 wurde wohl auf 100.000 Huawei Ascend-Chips trainiert. Nirgendwo Nvidia..
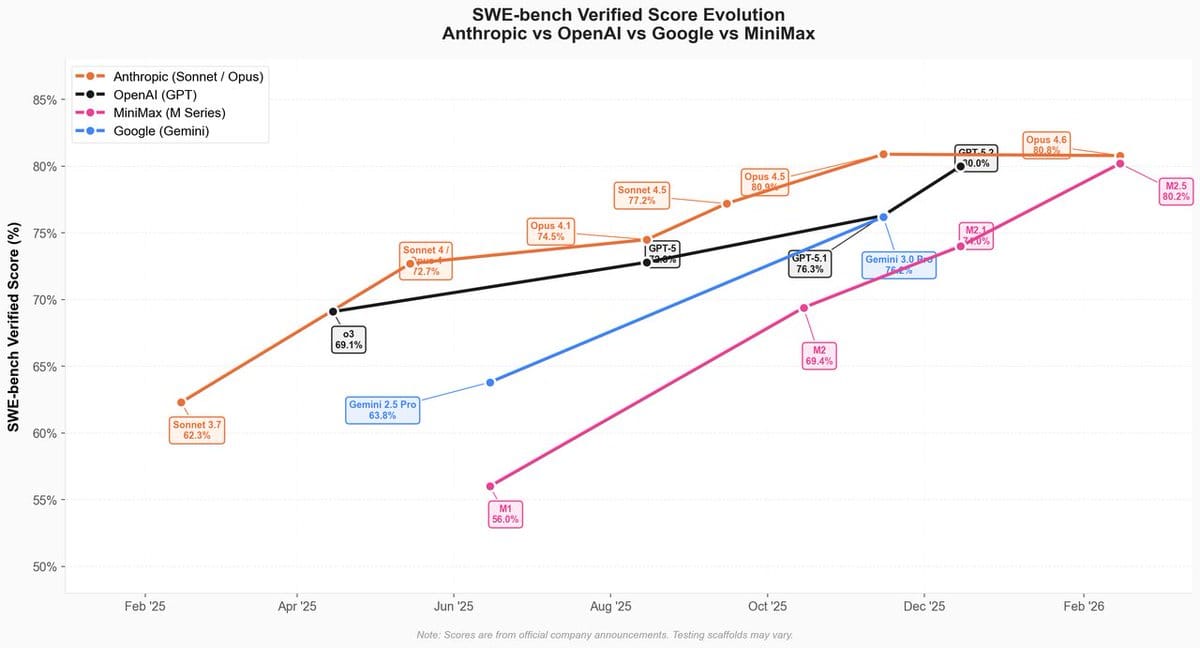
Besonders MiniMax 2.5 beeindruckt die Branche, es soll wohl ungefähr auf Augenhöhe mit Opus 4.6 liegen (während es um das 20-fache günstiger ist):
KI-Agenten; von Vibe Coding zu Agentic Engineering
Lesen Sie die ganze Geschichte
Melden Sie sich jetzt an, um die vollständige Geschichte zu lesen und Zugriff auf alle bezahlten Beiträge zu erhalten.
Abonnieren