



Hi,
well. Seufz.
Marcel
Zitat des Tages
A usually reliable source tells me that the North Korean soldiers who have deployed to Russia have never had unfettered access to the internet before. As a result, they are gorging on pornography.
🤖 KI
Wir brauchen eine KI-Infrastruktur!
Die besten Texte schreibe ich, wenn ich ein Thema habe und während der Recherche feststelle, dass dieses Thema eine größere Tragweite hat, wichtiger ist, als ursprünglich angenommen.
Für die FAZ habe ich über die Datencenter-Investitionen der großen Tech-Konzerne geschrieben, welche mittlerweile auch den Aufbau von Atomstromkraftwerken beinhaltet: Wir müssen über eine KI-Infrastruktur reden!
Es ist allseits bekannt, dass KI energiehungrig ist. Eine Folge davon ist, dass die großen Tech-Konzerne versuchen, direkt Atomstrom für ihre Datencenter zu gewinnen. Und dafür neue kleine Atomkraftwerke finanzieren wollen. (Mittlerweile sind bereits Meta als auch Amazon mit ihren ersten Anläufen an verschiedenen Regulierungen gescheitert. Nur Mircosoft kommt aktuell noch voran.)
Wenn wir der These der KI-Unternehmen und Techkonzerne folgen, dass KI eine neue Querschnittstechnologie ist, deren Bedeutung vielleicht sogar die des Internets übersteigt, dann müssen wir als Erstes aufhören, allein von Datencentern zu sprechen. Stattdessen müssen wir über KI-Infrastruktur sprechen. Infrastruktur, zu der Datencenter neben anderen Dingen wie Energieversorgung, Grundlagenforschung oder ein die Entwicklung unterstützender regulatorischer Rahmen gehören.
Wenn wir nur ein kleines bisschen extrapolieren, kommen wir zum Schluss, dass selbst die geringen Investitionen in neue Datencenter hierzulande zu viel Zusatzlast für das hiesige Stromnetz bedeuten können.
Wo ist die Energielösung für KI in Europa, in Deutschland?
Aus einem Blick auf die Tätigkeiten der US-Konzerne wird während des Schreibens die Erkenntnis, dass wir hier in Deutschland und Europa das Thema viel wichtiger nehmen müssen. Es geht nicht allein um Datencenter, es geht um den Aufbau einer Infrastruktur für KI. Und dazu gehört auch die Frage, wo die Energie herkommen soll.
Weder wirtschaftsseitig noch politisch ist das überhaupt ein Thema.
Im FAZ-Text erwähnte ich unter anderem, dass China vielleicht ein Datencenter nahe dem Drei-Schluchten-Staudamm, dem größten Wasserkraftwerk der Welt bauen könnte.
Letzte Woche habe ich im Economist gelesen, dass Bhutan, eine kleine Gebirgsnation nördlich von Indien zwischen Indien und China, eine "special administrative region" erbaut. Diese Region soll speziell ausländische Investoren anlocken. Bhutan will auch explizit KI-Investitionen anlocken. Das kleine Land hat Zugang zu 2,5GW Wasserkraft, die auf 30GW ausgebaut werden könnten. Das ist sehr viel. Das Wasserkraftwerk am Drei-Schluchten-Staudamm in China liegt bei 22,5 GW.
Bhutan, ein Land mit einem BIP von 2,9 Mia. $ und einer Bevölkerungsgröße von 791.524 Menschen, ist in seinen Überlegungen weiter als die EU.
KI in China
Passend zum Thema habe ich mich für die FAZ vor einem Monat auch mit KI in China beschäftigt. China hat keinen Zugang mehr zu den schnellsten NVIDIA-Chips, das scheint sie aber nur bedingt aufzuhalten.
Besonders herausfordern könnte es werden, wenn China es schafft, Modelltrainingsphasen über verschiedene Chips und Datencenter hinweg zu ermöglichen. Dann kommt das autokratische Moment zum Tragen:
Besonders eine erfolgreiche Kombination von Datencentern für das Training könnte die chinesische Regierung dazu verleiten, alle chinesischen Techunternehmen mit dafür relevanten Datencentern zu gemeinsamen Trainingsläufen für chinesische LLMs zu verdonnern.
Podcast mit SemiAnalysis und Asianometry über KI, Chip-Industrie und mehr
Ich kann zu diesen Themen und etwa der Chipindustrie nur wärmstens diese Folge eines Videopodcasts empfehlen, in denen Dylan Patel von SemiAnalysis und der Mensch hinter dem Videokanal Asianometry darüber reden, wie die Chipindustrie funktioniert und wo wir bei den Investitionen in KI stehen:
https://www.youtube.com/watch?v=pE3KKUKXcTM
@Asianometry & Dylan Patel – How the Semiconductor Industry Actually Works
Offene multimodale Modelle
In meinem regelmäßigen Blick auf die KI-Forschung habe ich jüngst in der FAZ auch auf offene Modelle geschaut, die möglicherweise auch in der EU einsetzbar sind:
Forscher an der University of Washington und dem für seine KI-Arbeit bereits bekannten Allen Institute for AI stellen einen ersten Aufschlag für offene multimodale LLMs vor: Die Molmo (Multimodal Open Language Model)-Modellfamilie soll mit freigegebenen Modellgewichten und freigegebenen Bildsprachentrainingsdaten ohne Rückgriff auf synthetische Daten von anderen VLMs erstellt worden sein (Vision Language Models, Sprachmodelle, die auch visuelle Daten verarbeiten). Die Forscher erwähnen außerdem explizit, dass keine Daten von proprietären VLMs einflossen. Es gibt also keine vererbten restriktiven Lizenzen, welche die Nutzung abgeleiteter Modelle einschränken könnten. Molmo ist offen im engsten Sinne von Open Source.
Paper: Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models (ArXiv, HTML,Begutachtung im Prozess)
Dazu passt diese Grafik von Peter Gostev auf LinkedIn:
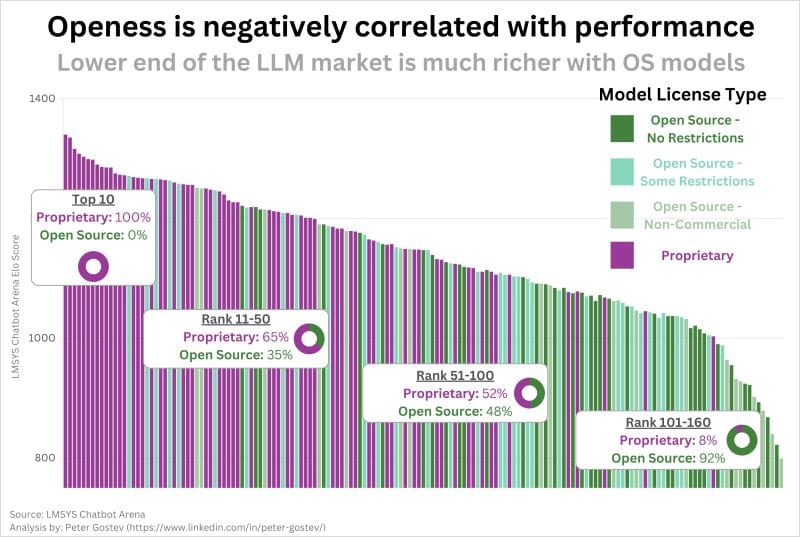
Die proprietären Modelle sind die besten Modelle. (laut LMSYS Chatbot Arena) Ich gehe davon aus, dass es sehr anders aussehen wird in ein paar Jahren, wenn sich Architekturen für Modellmixe etablieren und hochspezialisierte offene Modelle wichtiger geworden sind.
Öffentliche Texte von Perplexity
Dieser Text über die Gründe, warum die USA immer Dienstags im November wählt, hätte so auch auf der Website einer beliebigen deutschen Tageszeitung erscheinen können. Nur nicht komplett automatisiert erstellt. Und mit weniger verlinkten Quellen.
Discovery und "SEO" für LLMs
Speaking of LLM-Suchmaschinen wie Perplexity. Mein Text zu Optimierung für Auffindbarkeit in LLMs:
Die Domänenabhängigkeit eingesetzter Methoden betont eine allgemeine Trendentwicklung, die wir am Anfang dieses Textes angesprochen haben. Wir erleben gerade das schleichende Ende der Ära, in der eine Suchmaschine, also ein einzelnes Produkt eines Unternehmens, synonym mit dem Internet und der eigenen Auffindbarkeit im Netz verwendet wird.
Tiktok macht nicht nur Google-Tochter Youtube auf dem Werbemarkt zu schaffen. Bereits 2022 erklärte Prabhakar Raghavan, ein hochrangiger Google-Manager, dass interne Studien zeigten, dass etwa 40 Prozent der Generation Z Tiktok und Instagram für Suchanfragen nutzen, besonders bei lokalen Themen wie Restaurants.
Die Singularität von Google, die es synonym mit dem Internet machte, hat eine Anspruchshaltung vor allem bei Onlinepublishern erzeugt. Ein schönes Beispiel: The end of independent publishing and Giant Freakin Robot • GIANT FREAKIN ROBOT:
After relaunching GIANT FREAKIN ROBOT in 2019, the site grew to a readership of more than 20 million a month, through 2021 and 2022. Then Google decided they didn’t want independent publishers around anymore. Most entertainment keywords have now been given to one big company, whose numerous sites own the top slots for nearly every entertainment-related query of any substance.
No one can find our site to read it so that 20 million unique visitors is now a few thousand a month. Nearly every independently owned entertainment news publisher is in the same situation, in one way or another.
Wenn aus 20 Millionen Visitors ein paar Tausend werden, wenn eine Distributionsplattform ihre Algorithmen ändern, ist man dann als Publisher wirklich "independent"? Oder ist man vielmehr klein und abhängig?
Dieser Satz fasst den Blick auf Google perfekt zusammen:
Unfortunately, if you’ve read my account of that catastrophe, you know that instead of finding solutions I received a clear signal from Google that they have no intention of allowing anyone to see GIANT FREAKIN ROBOT’s work.
"allowing"? Die Publikation ist eine Website.
Die nächsten Jahre
Azeem Azhar auf Exponential View über "the Most Consequential US Election":
The further acceleration in artificial intelligence development will outpace even the remarkable progress of recent years. When I discussed it with AI leaders in Silicon Valley recently, I found a striking consensus: the current scaling methods that produce increasingly capable AI systems will remain effective for several years. The confidence in these scaling approaches has grown substantially in recent months. With firms now understanding the proven recipe for advancement, they are doubling down on their investments, which will result in an acceleration.
A fundamental shift is approaching in AI architecture, moving beyond today’s query-response model toward agent-based workflows. These systems will comprise networks of increasingly autonomous AI components working in concert. While such systems are in their early stages, they will likely experience their own “ChatGPT moment” during the next presidential term. This will catalyse a widespread economic transformation.
Auf dieser Transformer-Welle (die Architektur der LLMs) wird der Fortschritt bei anderen Technologien gerade ebenfalls schneller: selbstfahrende Autos, Robotik.
Die USA unter Trump dürfte hier vor allem von Deregulierung geprägt sein.
Je nachdem, wie viel Chaos die Administration verursacht, könnte das aber dank einer Wirtschaftskrise relativ wenig bewirken.
Die Themen der letzten Mitglieder-Ausgaben
🔥Nexus 232: Lilium, EU Inc, Tesla vs. Waymo, Musks Modus, TikTok verlegt Printbücher
- Lilium
- EU Inc.
- 🤖 KI
- 🛒 Onlinehandel
- 📺 Medienwandel und vernetzte Öffentlichkeit
- ✴️ Mehr Wissenswertes
🚌 Transportsektor
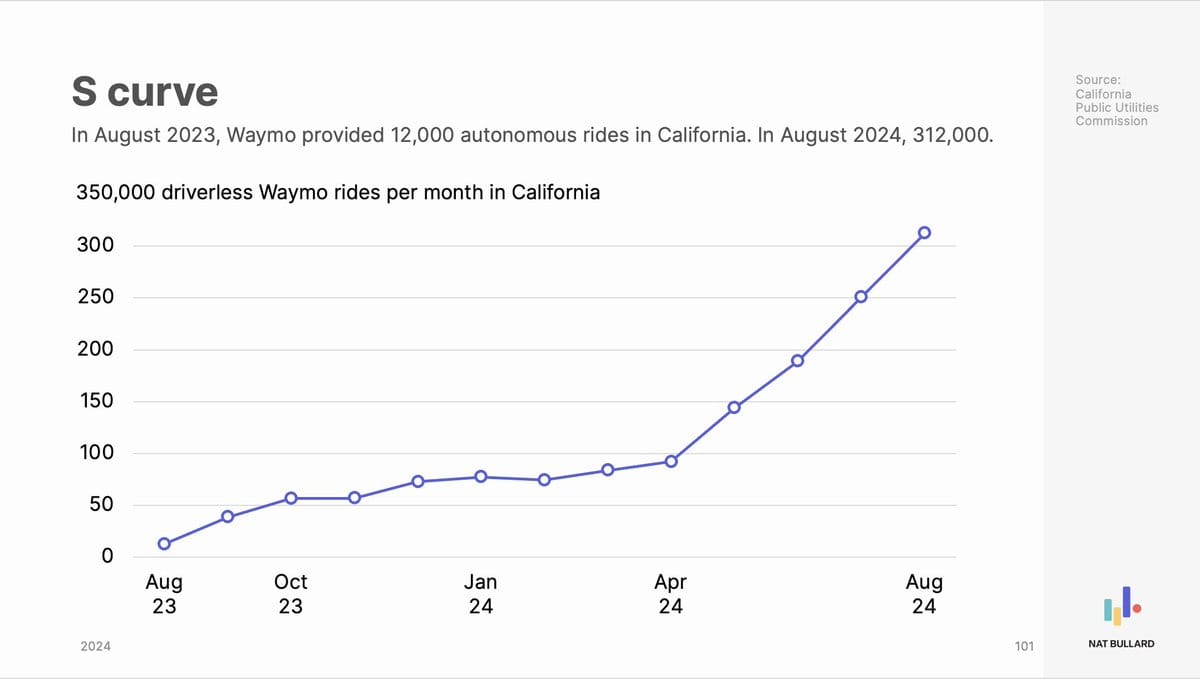
Waymo auf der S-Kurve
Waymo wird in den nächsten Jahren die größte Meta-Tochter nach YouTube werden und in naher Zukunft auch YouTube überholen:
Fahrerlose Fahrten:
In August 2023: 12,000 for the month.
In August 2024: 312,000 for the month.
Man kann es schon sehen, via X:
✴️ Mehr Wissenswertes
Das Gedankenspiel der unendlich vielen Affen wird von australischen Mathematikern in Frage gestellt. BBC:
Known as the "infinite monkey theorem", the thought-experiment has long been used to explain the principles of probability and randomness.
However, a new peer-reviewed study led by Sydney-based researchers Stephen Woodcock and Jay Falletta has found that the time it would take for a typing monkey to replicate Shakespeare's plays, sonnets and poems would be longer than the lifespan of our universe.
Which means that while mathematically true, the theorem is "misleading", they say.
Hier könnte auch eine Erkenntnis über LLMs drinstecken.
Shein-Zahlen für Europa. retail-news.de:
Die Umsätze der in Irland registrierten Einheit Infinite Styles Ecommerce Co., die für das Europageschäft zuständig ist und auch im deutschen Online-Shop im Impressum genannt ist, stiegen 2023 um 68 % und erreichten damit 7,68 Milliarden Euro.
Auch die Rentabilität in Europa legte deutlich zu. Der Gewinn nach Steuern von Sheins Irland-Einheit verdoppelte sich laut offiziellen Dokumenten auf 99,5 Millionen Euro gegenüber 45,8 Millionen Euro im Vorjahr. Der Bruttogewinn stieg von 172 Millionen Euro im Jahr 2022 auf 314 Millionen Euro in 2023.